
Scientific publication
T. M. Lange, M. Gültas, A. O. Schmitt & F. Heinrich (2025). optRF: Optimising random forest stability by determining the optimal number of trees. BMC bioinformatics, 26(1), 95. Follow this LINK to the original publication.
Random Forest — A Powerful Tool for Anyone Working With Data
What is Random Forest?
Have you ever wished you…
Quantization is one of the key techniques for reducing the memory footprint of large language models (LLMs). It works by converting the data type of model parameters from higher-precision formats such as 32-bit floating point (FP32) or 16-bit floating point (FP16/BF16) to lower-precision integer formats, typically INT8 or INT4. For example, quantizing a model to…
When I built a GPT-powered fashion assistant, I expected runway looks—not memory loss, hallucinations, or semantic déjà vu. But what unfolded became a lesson in how prompting really works—and why LLMs are more like wild animals than tools.
This article builds on my previous article on TDS, where I introduced Glitter as a proof-of-concept GPT…
Why you should read this
As someone who did a Bachelors in Mathematics I was first introduced to L¹ and L² as a measure of Distance… now it seems to be a measure of error — where have we gone wrong? But jokes aside, there seems to be this misconception that L₁ and L₂ serve the same function — and…

Are you feeling “fear of missing out” (FOMO) when it comes to LLM agents? Well, that was the case for me for quite a while.
In recent months, it feels like my online feeds have been completely bombarded by “LLM Agents”: every other technical blog is trying to show me “how to build an agent…
Introduction
AWS is a popular cloud provider that enables the deployment and scaling of large applications. Mastering at least one cloud platform is an essential skill for software engineers and data scientists. Running an application locally is not enough to make it usable in production — it must be deployed on a server to become…
Deploying your Large Language Model (LLM) is not necessarily the final step in productionizing your Generative AI application. An often forgotten, yet crucial part of the MLOPs lifecycle is properly load testing your LLM and ensuring it is ready to withstand your expected production traffic. Load testing at a high level is the practice of…
This article is part of a series of articles on automating data cleaning for any tabular dataset:
Effortless Spreadsheet Normalisation With LLM
You can test the feature described in this article on your own dataset using the CleanMyExcel.io service, which is free and requires no registration.
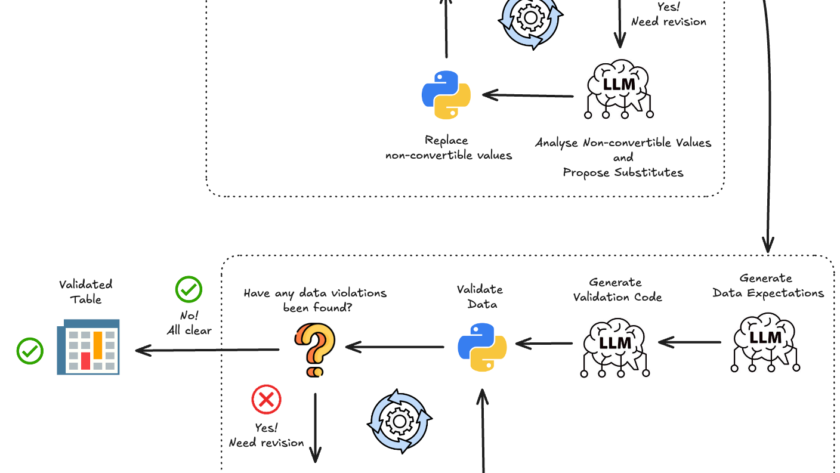
What is Data Validity?
Data validity refers to data…
Introduction
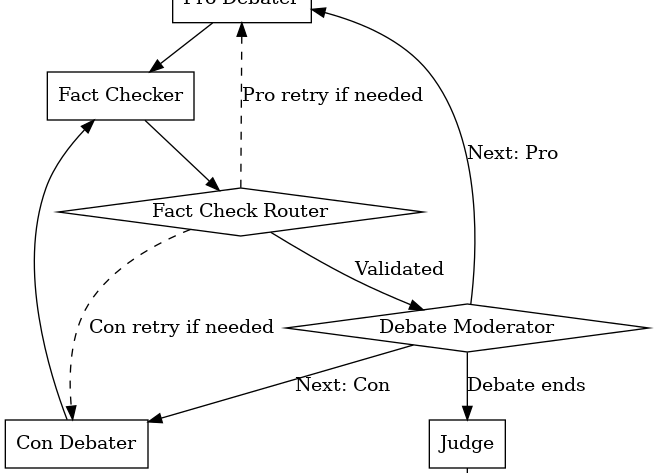
I’ve always been fascinated by debates—the strategic framing, the sharp retorts, and the carefully timed comebacks. Debates aren’t just entertaining; they’re structured battles of ideas, driven by logic and evidence. Recently, I started wondering: could we replicate that dynamic using AI agents—having them debate each other autonomously, complete with real-time fact-checking and moderation? The…

According to various sources, the average salary for Coding jobs is ~£47.5k in the UK, which is ~35% higher than the median salary of about £35k.
So, coding is a very valuable skill that will earn you more money, not to mention it’s really fun.
I have been coding professionally now for 4 years, working…